Composants d'infrastructure
L’infrastructure est destinée à supporter deux types d’applications :
- Les applications consommant principalement des cycles processeur (Compute-intensive applications),
- Les applications consommant intensivement des données (Data-intensive applications). Une application consommant principalement des données est rarement limitée par la puissance du CPU, mais plus souvent par la quantité et la complexité des structures de données, et la vitesse à laquelle celles-ci doivent être échangées cite:[data_intensive(3)].
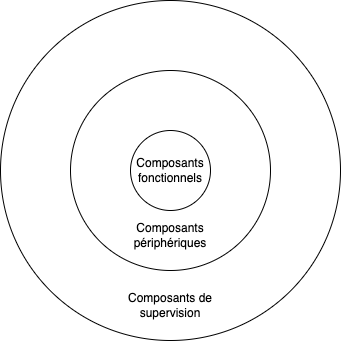
Au niveau des composants destinés à épauler ces applications, nous pouvons distinguer les types suivants :
- Les composants fonctionnels, ceux sans qui l’application fonctionnerait de manière partielle, inadéquate, ou avec des temps de réponse inadaptés,
- Les composants périphériques, c’est-à-dire les composants qui aident à avoir une architecture système résiliente, évolutive et maintenable,
- Les composants de supervision, qui permettent de s’assurer que tout fonctionne correctement, et qu’aucun incident n’est prévu ou n’a été constaté récemment.
Il faut voir ceci comme un gros gâteau, où la supervision est appliquée sur les étages fonctionnels et périphériques
L’objectif est de construire une infrastructure Production-ready, en essayant déjà de couvrir au maximum les erreurs qui pourraient survenir. Plus précisément :
- Opérations: Sécurité, disponibilité, capacité, statuts et communication.
- Flight Control : Monitoring, déploiements, détections d’anomalies, nouvelles fonctionnalités.
- Interconnexions : Routage, load balancing, failover, gestion du trafic,
- Instances : Services, processus, composants,
- Fondations : Hardware, machines virtuelles, adresses IP, réseau physique.
Nous noterons également que beaucoup de composants sont des composants open-source - cf. https://xkcd.com/2347/
Composants fonctionnels
Une architecture possible pour un système de données moderne, qui combine plusieurs composants cite:[data_intensive(5)]
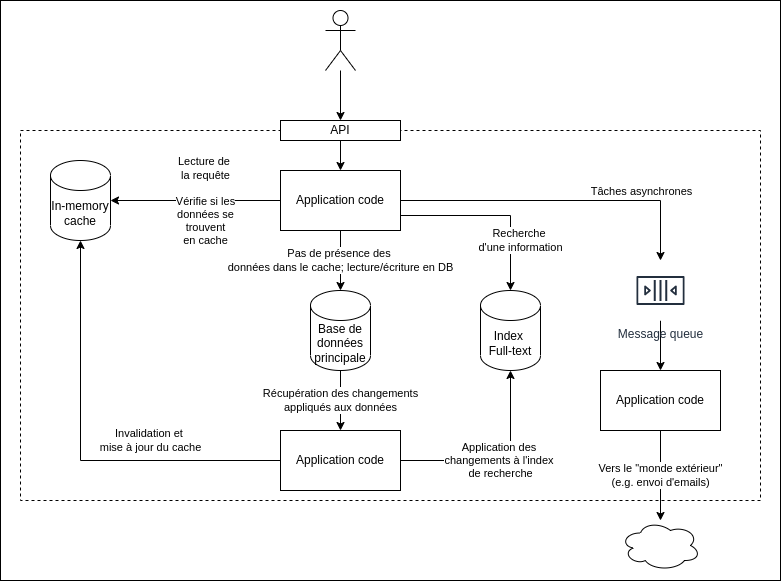
Une application data-intensive est généralement composée des blocs fonctionnels suivants, de manière non-exhaustive cite:[data_intensive(3)] :
| Type | Utilité | Exemples |
|---|---|---|
| Bases de données | Stocker des données, pour pouvoir les retrouver (elles-même ou une autre application) plus tard | PostgreSQL, MySQL, MariaDB, SQLite |
| Caches | Conserver en mémoire des résultats gourmands, afin de pouvoir les réexploiter plus rapidement, sans avoir à les recalculer | Redis, Memcache |
| Moteurs d’indexation | Autoriser la recherche de résultats sur base de mots-clés ou en utilisant des filtres particuliers | ElasticSearch, Solr |
| Traitements asynchrones | Exécution de traitements lourds ou pouvant être démarrés a posteriori | Celery |
Vous noterez que l’ensemble des composants utilisés sont Open source :
When I built my first company starting in 1999, it cost $2.5 million in infrastructure just to get started and another $2.5 million in team costs to code, launch, manage, market and sell our software […].
The first major change in our industry was imperceptible to us as an industry. It was driven by the introduction of open-source software, most notably what was called the LAMP stack. Linux (instead of UNIX), Apache (web server software), MySQL (instead of Oracle) and PHP. Of course there were variants - we preferred PostGres to MySQL and many people used other programming languages than PHP.
Open source became a movement - a mentality: Suddenly infrastructure software was nearly free. We paid 10% of the normal costs for the software and that money was software support. A 90% disruption in cost spawns innovation - believe me.
— Mark Suster
Dans tous les cas, la disponibilité de logiciels et librairies open source, ainsi que des plateformes d’hébergements (comme Amazon Web Services ou Heroku) plus accessibles signifient qu’une startup n’a plus besoin d’investir des millions pour démarrer.
Bases de données
TBC
Caches
TBC
Moteurs d’indexation
TBC
Traitements asynchrones
TBC
Composants périphériques
Les composants périphériques gravitent autour du fonctionnement normal de l’application. Ce sont les “petites mains” qui aident à ce que l’application soit résiliente ou que la charge soit amoindrie ou répartie entre plusieurs instances. Il s’agit des composants comme un proxy inverse ou les répartiteurs de charge : ce sont des composants qui ne sont pas pas obligatoires au bon fonctionnement de l’application, mais fortement recommandés quand même.

Focusing on resilience” often means that a firm can handle events that may cause crises for most organizations in a manner that is routine and mundane cite:[devops(282)].
Cette résilience est obtenue en applicant des schémas spécifiques, incluant notamment les modèles suivants :
- Fail-Fast : Mise en place de timeouts aggressifs pour que, si l’application devait planter, elle le fasse rapidement.
- Fallbacks : Faire en sorte que la qualité fournie par chaque fonctionnalité puisse être dégradée, mais que cette fonctionnalité continue à tourner,
- Feature removals : Autoriser à retirer certaines fonctionnalités non-critiques lorsqu’elles tournent plus lentement, afin de limiter l’impact qu’elle pourrait avoir sur l’expérience utilisateur.
Avoir des composants périphériques correctement configurés permet d’anticiper certaines erreurs, et donc d’augmenter la résilience de l’application. Certaines plateformes, comme Amazon Web Services, favorisent la flexibilité et l’eslasticité plutôt que la disponibilité d’une seule machine. C’est donc une bonne idée de faire en sorte que des erreurs d’indisponibilité peuvent arriver. Netflix a par exemple développer le Chaos Monkey, qui s’occupe d’éteindre au hasard des machines virtuels et containers dans un environnement de production, juste pour faire en sorte que les équipes soient drillées à développer toutes sortes de mécanismes de remise en service..
| Type | Utilité | Exemples |
|---|---|---|
| Firewall | firewalld, UFW | |
| Reverse Proxy | Nginx, Apache | |
| Load balancers | Distribution de la charge sur plusieurs serveurs, en fonction du nombre d’utilisateurs, du nombre de requêtes à gérer et du temps que prennent chacune d’entre elles | HAProxy |
| Serveurs d’application | Gunicorn, Uvicorn |
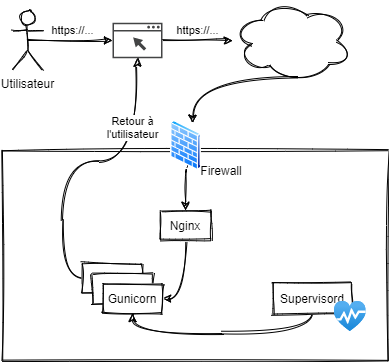
Si nous schématisons l’infrastructure et le chemin parcouru par une requête, nous pourrions arriver à la synthèse suivante :
- L’utilisateur fait une requête via son navigateur (Firefox ou Chrome),
- Le navigateur envoie une requête http, sa version, un verbe (GET, POST, …), un port et contenu,
- Le firewall du serveur (Debian GNU/Linux, CentOS, …vérifie si la requête peut être prise en compte,
- La requête est transmise à l’application qui écoute sur le port (probablement 80 ou 443; et a priori Nginx),
- Elle est ensuite transmise par socket et est prise en compte par un des workers (= un processus Python) instancié par Gunicorn. Si l’un de ces travailleurs venait à planter, il serait automatiquement réinstancié par Supervisord,
- Qui la transmet ensuite à l’un de ses workers (= un processus Python),
- Après exécution, une réponse est renvoyée à l’utilisateur.
Firewall
TBC
Reverse proxy
Le principe du proxy inverse est de pouvoir rediriger du trafic entrant vers une application hébergée sur le système. Il serait tout à fait possible de rendre notre application directement accessible depuis l’extérieur, mais le proxy a aussi l’intérêt de pouvoir élever la sécurité du serveur (SSL) et décharger le serveur applicatif grâce à un mécanisme de cache ou en compressant certains résultats https://fr.wikipedia.org/wiki/Proxy_inverse
Répartiteur de charge (Load balancer)
Les répartiteurs de charges sont super utiles pour donner du mou à l’infrastructure:
- Maintenance et application de patches,
- Répartition des utilisateurs connectés,
- …
Serveurs d’application (Workers)
Processus et threads.
Au niveau logiciel (la partie mise en subrillance ci-dessus), la requête arrive dans les mains du processus Python, qui doit encore
- Effectuer le routage des données,
- Trouver la bonne fonction à exécuter,
- Récupérer les données depuis la base de données,
- Effectuer le rendu ou la conversion des données,
- Renvoyer une réponse à l’utilisateur.
Composants de supervision
| Type | Utilité | Exemples |
|---|---|---|
| Supervision des processus | Supervisord | |
| Flux d’évènements | syslogd, journalctl | |
| Notifications | Zabbix, Nagios, Munin | |
| Télémétrie |
Supervision des processus
https://circus.readthedocs.io/en/latest/, https://uwsgi-docs.readthedocs.io/en/latest/, statsd
When we crash an actor or a process, how does a new one get started ? You could write a bash script with a while() loop in it. But what happens when the problem persists across restarts ? The script basically fork-bombs the server.
Actors system use a hierarchical tree of supervisors to manage the restarts. Whenever an actor terminates, the runtime notifies thesupervisor. The supervisor can then decide to restart the child actor, restart all of its children, or crash itself. If the supervisor crashes, the runtime will terminate all its children and notify the supervisor’s supervisor. Ultimately you can get while branches of the supervision tree to restart with a clean state.
Journaux d’évènements
La présence de journaux, leur structure et de la définition précise de leurs niveaux est essentielle; ce sont eux qui permettent d’obtenir des informations quant au statut de l’application:
- Que fait-elle pour le moment ?
- Qu’a-t-elle fait à un moment en particulier ?
- Depuis quand n’a-t-elle plus émis de nouveaux évènements ?
When deciding whether a message should be ERROR or WARN, imagine being woken up at 4 a.m. Low printer toner is not an ERROR.
Dan North (ToughtWorks)
Chaque évènement est associé à un niveau; celui-ci indique sa criticité et sa émet un premier tri quant à sa pertinence.
- DEBUG: Il s’agit des informations qui concernent tout ce qui peut se passer durant l’exécution de l’application. Généralement, ce niveau est désactivé pour une application qui passe en production, sauf s’il est nécessaire d’isoler un comportement en particulier, auquel cas il suffit de le réactiver temporairement.
- INFO: Enregistre les actions pilotées par un utilisateur - Démarrage de la transaction de paiement, …
- WARN: Regroupe les informations qui pourraient potentiellement devenir des erreurs.
- ERROR: Indique les informations internes - Erreur lors de l’appel d’une API, erreur interne, …
- FATAL (ou EXCEPTION): …généralement suivie d’une terminaison du programme - Bind raté d’un socket, etc.
Télémétrie
Des erreurs sur un environnement de production arriveront, tôt ou tard, et seront sans doute plus compliquée à corriger qu’un morceau de code dans un coin du code. L’exploitation des journaux permettra de comprendre, analyser, voire corriger, certains incidents.
Comme nous l’avons vu, en fonction de l’infrastructure choisie, il existe plusieurs types de journaux:
- Les journaux applicatifs: ie. le flux d’évènements généré par votre application Django
- Les journaux du serveur: Nginx, Gunicorn, …
- Les journaux des autres composants: base de données, service de mise en cache, …
Une manière de faire consiste à se connecter physiquement ou à distance à la machine pour analyser les logs. En pratique, c’est impossible : entre les répartiteurs de charge, les différents serveurs, …, il vous sera impossible de récupérer une information cohérente, croisée entre tous les différents composants. La solution consiste à agréger vos journaux à un seul et même endroit :
.mattsegal.dev/django-monitoring-stack.html
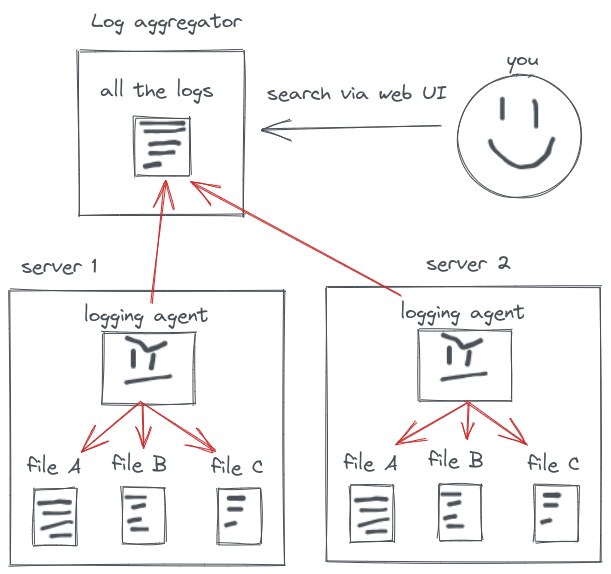
Sumologic
TBC
Alternatives
Il existe également Munin, Logstash, ElasticSearch et Kibana (ELK-Stack) ou Fluentd.
La récupération de métriques augmente la confiance que l’on peut avoir dans la solution. L’analyse de ces métriques garantit un juste retour d’informations, sous réserve qu’elles soient exploitées correctement. La première étape consiste à agréger ces données dans un dépôt centralisé, tandis que la seconde étape exigera une structuration correcte des données envoyées.
La collecte des données doit récupérer des données des couches métiers, applicatives et d’environnement. Ces données couvrent les évènements, les journaux et les métriques - indépendamment de leur source - le pourcentage d’utilisation du processeur, la mémoire utilisée, les disques systèmes, l’utilisation du réseau, …
- Métier: Le nombre de ventes réalisées, le nombre de nouveaux utilisateurs, les résultats de tests A/B, …
- Application: Le délai de réalisation d’une transaction, le temps de réponse par utilisateur, …
- Infrastructure: Le trafic du serveur Web, le taux d’occupation du CPU, …
- Côté client: Les erreurs applicatives, les transactions côté utilisateur, …
- Pipeline de déploiement*: Statuts des builds, temps de mise à disposition d’une fonctionnalité, fréquence des déploiements, statuts des environnements, …
Bien utilisés, ces outils permettent de prévenir des incidents de manière empirique.
Monitoring is so important that our monitoring systems need to be more available and scalable than the systems being monitored.
— Adrian Cockcroft
Histoire de schématiser, toute équipe se retrouve à un moment où un autre dans la situation suivante: personne ne veut appuyer sur le gros bouton rouge issu de l’automatisation de la chaîne de production et qui dit “Déploiement”. Et pour cause: une fois que nous aurons trouvé une joyeuse victime qui osera braver le danger, il y aura systématiquement des imprévus, des petits détails qui auront été oubliés sur le côté de la route, et qui feront lâchement planter les environnements. Et puisque nous n’aurons pas (encore) de télémétrie, le seul moment où nous comprendrons qu’il y a un problème, sera quand un utilisateur viendra se plaindre.
Statsd
https://www.datadoghq.com/blog/statsd/
Conclusions
TBC