Modélisation
Ce chapitre aborde la modélisation des objets et les options qui y sont liées.
Avec Django, la modélisation est en lien direct avec la conception et le stockage, sous forme d’une base de données relationnelle, et la manière dont ces données s’agencent et communiquent entre elles.
“Le modèle n’est qu’une grande hypothèse. Il se base sur des choix conscients et inconscients, et dans chacun de ces choix se cachent nos propres perceptions qui résultent de qui nous sommes, de nos connaissances, de nos profils scientifiques et de tant d’autres choses.”
Django utilise un paradigme de persistence des données de type ORM - c’est-à-dire que chaque type d’objet manipulé peut s’apparenter à une table SQL, tout en respectant une approche propre à la programmation orientée objet. Plus spécifiquement, l’ORM de Django suit le patron de conception Active Records, comme le font par exemple Rails pour Ruby ou EntityFramework pour .Net.
Le modèle de données de Django est sans doute la seule partie qui soit tellement couplée au framework qu’un changement à ce niveau nécessitera une refonte complète de beaucoup d’autres briques de vos projets; là où un pattern de type Repository permettrait justement de découpler le modèle des données de l’accès à ces mêmes données, un pattern Active Record lie de manière extrêmement forte le modèle à sa persistence.
Architecturalement, c’est sans doute la plus grosse faiblesse de Django, à tel point que ne pas utiliser cette brique de fonctionnalités peut remettre en question le choix du framework (et pour ces cas-là, il existe des alternatives comme Flask, qui permettent une flexibilité et un choix des composants beaucoup plus grand.
Conceptuellement, c’est pourtant la manière de faire qui permettra d’avoir quelque chose à présenter très rapidement: à partir du moment où vous aurez un modèle de données, vous aurez accès, grâce à cet ORM à:
- Des migrations de données et la possibilité de faire évoluer votre modèle en corrélation avec votre couche de persistance,
- Une abstraction entre votre modélisation et la manière dont les données sont représentées via un moteur de base de données relationnelles,
- Une interface d’administration auto-générée,
- Un mécanisme de formulaires HTML complet, pratique à utiliser, orienté objet et logique à faire évoluer,
- Une définition des notions d’héritage (tout en restant dans une forme d’héritage simple).
Comme tout ceci reste au niveau du code, cela suit également la méthodologie des douze facteurs concernant la minimisation des divergences entre environnements d’exécution: il n’est plus nécessaire d’avoir un DBA qui doive démarrer un script sur un serveur au moment de la mise à jour, de recevoir une release note de 512 pages en PDF reprenant les modifications ou de nécessiter l’intervention de trois équipes différentes lors d’une modification majeure du code.
Déployer une nouvelle instance de l’application pourra être réalisé directement à partir d’une seule et même commande.
Active Records
Il est important de noter que l’implémentation d’Active Records reste une forme hybride entre une structure de données brutes et une classe:
- Une classe va exposer ses données derrière une forme d’abstraction et une forme de modélisation orientée sur le comportement, en n’exposant que les fonctions qui opèrent ses ces données ;
- Une structure de données ne va exposer que ses champs et propriétés et ne va pas avoir de functions significatives.
L’exemple ci-dessous présente trois structure de données, qui exposent chacune leurs propres champs :
class Square: def __init__(self, top_left, side): self.top_left = top_left self.side = side
class Rectangle: def __init__(self, top_left, height, width): self.top_left = top_left self.height = height self.width = width
class Circle: def __init__(self, center, radius): self.center = center self.radius = radiusSi nous souhaitons ajouter une fonctionnalité permettant de calculer l’aire pour chacune de ces structures, nous aurons deux possibilités :
- Soit ajouter une classe de visite qui ajoute cette fonction de calcul d’aire
- Soit modifier notre modèle pour que chaque structure hérite d’une classe de type
Shape, qui implémentera elle-même ce calcul d’aire.
Visitor
Dans le premier cas, nous pouvons procéder de la manière suivante:
class Geometry: PI = 3.141592653589793
def area(self, shape): if isinstance(shape, Square): return shape.side * shape.side
if isinstance(shape, Rectangle): return shape.height * shape.width
if isinstance(shape, Circle): return PI * shape.radius**2
raise NoSuchShapeException()Notions d’héritage
Dans le second cas, l’implémentation pourrait évoluer de la manière suivante:
class Shape: def area(self): pass
class Square(Shape): def __init__(self, top_left, side): self.__top_left = top_left self.__side = side
def area(self): return self.__side * self.__side
class Rectangle(Shape): def __init__(self, top_left, height, width): self.__top_left = top_left self.__height = height self.__width = width
def area(self): return self.__height * self.__width
class Circle(Shape): def __init__(self, center, radius): self.__center = center self.__radius = radius
def area(self): PI = 3.141592653589793 return PI * self.__radius**2Une structure de données peut être rendue abstraite au travers des notions de programmation orientée objet.
Dans l’exemple géométrique ci-dessus, repris de , l’accessibilité des champs devient restreinte, tandis que la fonction area() bascule comme méthode d’instance plutôt que de l’isoler au niveau d’un visiteur.
Nous ajoutons une abstraction au niveau des formes grâce à un héritage sur la classe Shape; indépendamment de ce que nous manipulerons, nous aurons la possibilité de calculer son aire.
Une structure de données permet de facilement gérer des champs et des propriétés, tandis qu’une classe gère et facilite l’ajout de fonctions et de méthodes.
Le problème d’Active Records est que chaque classe s’apparente à une table SQL et revient donc à gérer des DTO ou Data Transfer Object, c’est-à-dire des objets de correspondance pure et simple entre les champs de la base de données et les propriétés de la programmation orientée objet, c’est-à-dire également des classes sans fonctions. Or, chaque classe a également la possibilité d’exposer des possibilités d’interactions au niveau de la persistence, en enregistrant ses propres données ou en en autorisant leur suppression. Nous arrivons alors à un modèle hybride, mélangeant des structures de données et des classes d’abstraction, ce qui restera parfaitement viable tant que l’on garde ces principes en tête et que l’on se prépare à une éventuelle réécriture du code.
Lors de l’analyse d’une classe de modèle, nous pouvons voir que Django exige un héritage de la classe django.db.models.Model.
Nous pouvons regarder les propriétés définies dans cette classe en analysant le fichier lib\site-packages\django\models\base.py.
Outre que models.Model hérite de ModelBase au travers de https://pypi.python.org/pypi/six[six] pour la rétrocompatibilité vers Python 2.7, cet héritage apporte notamment les fonctions save(), clean(), delete(), …
En résumé, toutes les méthodes qui font qu’une instance sait comment interagir avec la base de données.
Types de champs, relations et clés étrangères
Nous l’avons vu plus tôt, Python est un langage dynamique et fortement typé. Django, de son côté, ajoute une couche de typage statique exigé par le lien sous-jacent avec les moteurs de base de données relationnelles.
Chaque champ du modèle est donc typé et lié, soit à un type primitif, soit à une autre instance au travers d’une relation. Les types primitifs regroupent les champs suivants :
| Type de champ | Description | Exemple |
|---|---|---|
| IntegerField | Entier | 1 |
| CharField | Chaîne de caractères | ”James Bond”, “Hello, world!” |
| TextField | Texte (sur plusieurs lignes) | Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Maecenas sed enim ut sem viverra aliquet eget sit. |
| DateField | Date | 12/06/2023, 03/07/1982, … |
| DateTimeField | Date et moment | 12/07/1986 07h23 |
| TimeField | Moment | 08h27 et 59 secondes |
| BooleanField | Valeur booléenne | True, False |
| DecimalField | Nombres décimaux | 12.0, 87.92, … |
| FloatField | Nombres flottants | π, … |
| DurationField | Durée et intervalles de temps (généralement en lien avec l’objet timedelta) | 3 mois et 2 jours, … |
| EmailField | Adresses emails | admin@mi6.co.uk |
| IPField | Adresses IP | :ffff:192.0.2.1, 192.0.2.1, … |
| URLField | L’emplacement d’une ressource (et son protocol) | https://my-app.fly.io |
| JsonField | {"key": "value"} | |
| UuidField |
Chacun de ces champs dispose de sa représentation au travers d’une classe, ainsi qu’un comportement qui lui est propre.
Ce comportement englobe une représentation visuelle (que nous verrons plus tard), un ensemble de validateurs (un champ EmailField par exemple, n’est jamais qu’un champ de type CharField sur lequel une vérification de présence du caractère @ est faite), …).
A ces types de base s’ajoute la possibilité de gérer des relations :
- Soit des relations
1-1grâce à un champ de typeOneToOneField, c’est-à-dire qu’un type d’objet n’a pour relation qu’une et une seule occurrence d’un autre type d’objet, - Soit des relations
1-ngrâce à un champ de typeForeignKeyField, où un objet d’un typeAn’a qu’une seule possibilité de choix parmi l’ensemble des enregistrements d’un typeB- par inversion, cet autre élément dispose de relations vers plusieurs éléments de l’ensembleA. - Soit des relations
n-mvia un champ de typeManyToManyField, où chaque occurrence deAouBpeut être liée à plusieurs de (respectivement)AouB.
Grâce à toutes ces informations, nous sommes en mesure de représenter facilement des relations, par exemple des livres liés à des catégories :
class Category(models.Model): name = models.CharField(max_length=255)
class Book(models.Model): title = models.CharField(max_length=255) category = models.ForeignKey(Category, on_delete=models.CASCADE)Les autres champs nous permettent d’identifier une catégorie (Category) par un nom (name), tandis qu’un livre (Book) le sera par ses propriétés title et une clé de relation vers une catégorie.
Chaque livre est donc lié à une catégorie, tandis qu’une catégorie est associée à plusieurs livres.
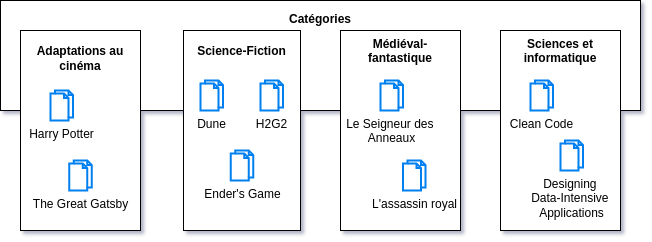
L’exemple présenté ci-dessus est volontairement simpliste. Nous pourrions gérer les auteurs, les acteurs, le synopsis, la date de sortie, les potentielles réédiditions, … mais il est évident que “toute modélisation reste une approximation de la réalité” cite:[other_side] et que nous n’avons pas besoin d’aller plus loin pour définir les bases de cette modélisation, qui servira d’exemple durant tout ce chapitre.
Structure des tables
A présent que notre structure dispose de sa modélisation, il nous faut informer le moteur de base de données de créer la structure correspondance, grâce à la création d’une étape de migration :
$ python manage.py makemigrations
Migrations for 'library': library/migrations/0001_initial.py - Create model Category - Create model BookCette étape créera un fichier reprenant les différences entre avant et après les modifications, explicitant ce qui doit être appliqué à la structure de données pour rester en corrélation avec la modélisation de notre application.
Chaque migration est automatiquement associé à un rollback qui permet de revenir à l’étape précédente, si un problème venait à apparaitre.
Toutes les migrations en attente sont appliquées (en une fois) grâce à la commande python manage.py migrate :
$ python manage.py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, library, sessionsRunning migrations: Applying library.0001_initial... OKNous pouvons à présent écrire un premier code d’initialisation.
Ouvrez un shell avec la commande python manage.py shell, et écrivez le code suivant :
from library.models import Book, Category
movies = Category.objects.create(name="Adaptations au cinéma")medieval = Category.objects.create(name="Médiéval-Fantastique")science_fiction = Category.objects.create(name="Sciences-fiction")computers = Category.objects.create(name="Sciences Informatiques")
books = { "Harry Potter": movies, "The Great Gatsby": movies, "Dune": science_fiction, "H2G2": science_fiction, "Ender's Game": science_fiction, "Le seigneur des anneaux": medieval, "L'Assassin Royal": medieval, "Clean code": computers, "Designing Data-Intensive Applications": computers}
for book_title, category in books.items(): Book.objects.create(title=book_title, category=category)Si tout va bien (et tout ira bien), vous recevrez la sortie suivante, qui confirmera que nos instances ont bien été créées :
<Book: Book object (1)><Book: Book object (2)><Book: Book object (3)><Book: Book object (4)><Book: Book object (5)><Book: Book object (6)><Book: Book object (7)><Book: Book object (8)><Book: Book object (9)>Nous nous rendons rapidement compte qu’un livre peut appartenir à plusieurs catégories:
- Dune a été adapté au cinéma en 1973 et en 2021, de même que Le Seigneur des Anneaux. Ces deux titres (au moins) peuvent appartenir à deux catégories distinctes.
- Pour The Great Gatsby, c’est l’inverse: nous l’avons initialement classé comme film, mais le livre existe depuis 1925.
- Nous pourrions sans doute également étoffer notre bibliothèque avec une catégorie supplémentaire “Baguettes magiques et trucs phalliques”, à laquelle nous pourrons associer la saga Harry Potter et ses dérivés.
En clair, notre modèle n’est pas adapté, et nous devons le modifier pour qu’une occurrence d’un livre puisse être liée à plusieurs catégories.
Au lieu d’utiliser un champ de type ForeignKey, nous utiliserons à présent un champ de type ManyToMany, c’est-à-dire qu’un livre pourra être lié à plusieurs catégories, et qu’inversément, une même catégorie pourra être liée à plusieurs livres :
class Category(models.Model): name = models.CharField(max_length=255)
class Book(models.Model): title = models.CharField(max_length=255) categories = models.ManyManyField(Category) <1>Nous utilisons à présent un champ de type ManyToManyField avec une cardinalité n-m, plutôt qu’une ForeignKey ayant une cardinalité 1-n. A noter que l’attribut on_delete ne peut pas être défini pour ce type-ci, et que nous avons “plurieliser” la propriété pour la transformer de category en categories.
Nous avons besoin de créer la migration, puis de l’appliquer :
$ python manage.py makemigrations
Migrations for 'library': library/migrations/0002_auto_20230613_1713.py - Remove field category from book - Add field categories to book
$ python manage.py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, library, sessionsRunning migrations: Applying library.0002_auto_20230613_1713... OKNotre code d’initialisation doit par contre être adapté :
- Django ne récupère pas automatiquement les données - ce devra être géré au travers d’une opération, lors de la migration,
- La manière dont les données sont associées doit être adaptée : nous passons d’une clé étrangère à des relations multiples ; il convient d’adapter cette partie également.
from library.models import Book, Category
movies, _ = Category.objects.get_or_create(name="Adaptations au cinéma") <1>medieval, _ = Category.objects.get_or_create(name="Médiéval-Fantastique")science_fiction, _ = Category.objects.get_or_create(name="Science-fiction")computers, _ = Category.objects.get_or_create(name="Sciences Informatiques")
books = { "Harry Potter": movies, "The Great Gatsby": movies, "Dune": science_fiction, "H2G2": science_fiction, "Ender's Game": science_fiction, "Le seigneur des anneaux": medieval, "L'Assassin Royal": medieval, "Clean code": computers, "Designing Data-Intensive Applications": computers}
for book_title, category in books.items(): book = Book.objects.get(title=book_title) <2> book.categories.add(category)- Comme nous savons que les catégories existent, nous utilisons la méthode
get_or_create()plutôt quecreate(). Cette méthode nous retourne deux valeurs : 1/ l’instance répondant aux critères de recherche ou de création et 2/ un booléen indiquant si cette instance a dû être créée ou non. - De la même manière, nous récupérons directement le livre correspondant au titre grâce à la méthode
get()alors que nous utilisions également une méthodecreate()lors de notre première version.
Compositions et filtres
L’ORM de Django est capable de traduire un chaînage de plusieurs méthodes en une ou plusieurs requêtes SQL. L’exemple des livres et catégories que nous avons représenté ci-dessus va nous permettre d’analyser le comportement de ces différentes méthodes.
L’élément de base de chaque requête est une instance de la classe Queryset, qui consiste à chaîner les différents éléments de requêtes jusqu’à ce qu’ils soient réellement nécessaire.
La majorité des méthodes pouvant être appelées sur un queryset renvoie elle-même ce même queryset.
Ainsi, il est possible de :
- Chaîner les différents éléments afin de combiner certains critères,
- N’évaluer le résultat qu’au moment où il est réellement demandé.
Dans l’exemple ci-dessus, nous recherchons les catégories dont le nom est égal à “Science-fiction”, et nous en sélectionnons le premier, s’il existe :
from library.models import Category <1>
movies_adaptations_category = Category.objects.filter( <2> name="Science-fiction" <3>).first() <4>- Nous importons la définition de nos catégories de livres
- Chaque définition de classe héritant de
django.db.models.Model, dispose par défaut d’une propriété intituléeobjects, qui réalise réellement le lien avec le stockage de données - Nous appliquons un filtre, en lui passant un ensemble de paramètres nommés
- Nous récupérons uniquement le premier élément. Pour le même prix, nous aurions pu sélectionner le
Nous pourrions aussi décomposer notre interrogation de la manière suivante :
from library.models import Category
sciences_fiction = Category.objects.filter( name__contains="Science" <1>).filter( name__contains="fiction" <2>).first()- Nous recherons ici les catégories qui contiennent le terme “Science” (avec cette orthographe exacte)
- … et une fois que nous avons ce premier filtre, nous filtrons également sur le terme et qui contiennent également le terme “cinéma”
Chronologiquement, nous avons ceci :
from library.models import Category
Category.objects.filter(name__contains="Science")
<QuerySet [<Category: Category object (3)>, <Category: Category object (4)>]> <1>- La recherche du terme “Science” nous renvoie deux éléments : la catégorie de “Sciences Informatiques” et la catégorie de “Science fiction”.
from library.models import Category
Category.objects.filter(name__contains="Science").filter(name__contains="fiction")
<QuerySet [<Category: Category object (3)>]> <1>- La combinaison des termes “Science” et “fiction” nous renvoie ici un seul élément : un second filtre est appliqué sur le premier, pour réduire le périmètre uniquement aux catégories le terme “Science” et le terme “fiction”.
En analysant la requête effectuée, nous voyons bien qu’il y a une combinaison des deux filtres :
>>> from django.db import connection>>> connection.queries
[ { 'sql': 'SELECT "library_category"."id", "library_category"."name" FROM "library_category" WHERE ( "library_category"."name" LIKE \'%Science%\' ESCAPE \'\\\' AND "library_category"."name" LIKE \'%fiction%\' ESCAPE \'\\\' ) LIMIT 21', 'time': '0.001' }]L’exemple que nous avons vu ci-dessous ne combine que deux filtres extrêmement simples. SQL autorise des requêtes beaucoup plus complexes, que nous verrons un peu plus tard lorsque nous aborderons les querysets plus en détails.
Lorsque nous interrogeons la base de données, l’ORM ne nous retourne que les éléments typés sur la classe que nous avons utilisée.
Ainsi, utiliser la classe Book ne nous retournera que des éléments de ce type-là, même si vous avez effectué une recherche sur une relation de ces livres.
Commençons par créer une classe Author, qui nous permettra de représenter l’auteur d’un livre.
Il est clair qu’il aurait fallu un champ de type ManyToMany, mais pour faciliter la lecture, nous choisissons une ForeignKey:
class Author(models.Model): name = models.CharField(max_length=255)
class Book(models.Model): title = models.CharField(max_length=255) author = models.ForeignKey(Author, on_delete=models.CASCADE, null=True)Remplissons quelques données :
>>> from library.models import Author, Book>>> robin = Author.objects.create(name="Robin Hobb")>>> assassin_apprentice = Book.objects.create(title="L'Assassin Royal", author=robin)La recherche de l’ensemble des livres dont le nom de l’auteur contient “Hobb” se traduira de la manière suivante avec l’ORM de Django et en SQL, et nous renverra le résultat <QuerySet [L'Assassin Royal]> :
from library.models import Book
Book.objects.filter(author__name__icontains="hobb") <1>- A noter qu’il n’est pas nécessaire d’importer la classe
Authorpour appliquer une recherche impliquant des relations. Celles-ci sont entièrement dynamiques et évaluées à l’exécution du code.
[ { 'sql': """ SELECT "library_book"."id", <1> "library_book"."title", "library_book"."author_id" FROM "library_book" INNER JOIN "library_author" ON ("library_book"."author_id" = "library_author"."id") WHERE "library_author"."name" LIKE \'%robb%\' ESCAPE \'\\\' LIMIT 21""", 'time': '0.002' },]- En ayant appliqué une requête sur la classe
Book, nous ne récupérons que des instances de cette classe-ci spécifiquement, malgré la jointure.
Pour appliquer des recherches parmi les différentes relations d’un modèle, il suffit de chaîner les différents éléments grâce à un double underscore _ _ (sans espace).
Ainsi, pour trouver l’ensemble des livres dont le nom de l’auteur contient “robb”, il nous suffit de partir des livres, puis d’appliquer un filtre contenant (successivement) les éléments suivants : author__name, auquel nous suffixerons une clause de recherche:
icontainsiexactgtisnull=[True|False]- …
Nous verrons dans le chapitre sur les queryset et managers comment élaborer des requêtes plus complexes.
Représentation textuelle
from library.models import Book
Book.objects.all()nous retournera le résultat suivant : <QuerySet [<Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>, <Book: Book object (4)>, <Book: Book object (5)>, <Book: Book object (6)>, <Book: Book object (7)>, <Book: Book object (8)>, <Book: Book object (9)>]>, ce qui n’est pas super engageant.
De même, l’appel au premier élément de nos livres via Book.objects.first() nous retourne uniquement ceci : <Book: Book object (1)>.
Cela nous dit plus ou moins de quoi il s’agit (C’est un livre, et il porte l’identifiant 1), mais c’est aussi un peu de gâchis.
Nomenclature des relations
Depuis le code, à partir de l’instance de la classe Item, on peut donc accéder à la liste en appelant la propriété wishlist de notre instance.
A contrario, depuis une instance de type Wishlist, on peut accéder à tous les éléments liés grâce à <nom de la propriété>_set; ici item_set.
Lorsque vous déclarez une relation 1-1, 1-N ou N-N entre deux classes, vous pouvez ajouter l’attribut related_name afin de nommer la relation inverse.
class Wishlist(models.Model): pass
class Item(models.Model): wishlist = models.ForeignKey(Wishlist, related_name='items')Si, dans une classe A, plusieurs relations sont liées à une classe B, Django ne saura pas à quoi correspondra la relation inverse.
Pour palier à ce problème, nous fixons une valeur à l’attribut related_name.
Par facilité (et par conventions), prenez l’habitude de toujours ajouter cet attribut: votre modèle gagnera en cohérence et en lisibilité.
Si cette relation inverse n’est pas nécessaire, il est possible de l’indiquer (par convention) au travers de l’attribut related_name="+".
A partir de maintenant, nous pouvons accéder à nos propriétés de la manière suivante:
# python manage.py shell
>>> from wish.models import Wishlist, Item>>> wishlist = Wishlist.create('Liste de test', 'description')>>> item = Item.create('Element de test', 'description', w)>>>>>> item.wishlist<Wishlist: Wishlist object>>>>>>> wishlist.items.all()[<Item: Item object>]Formes d’héritage
On constate que plusieurs classes possèdent les mêmes propriétés created_at et updated_at, initialisées aux mêmes valeurs.
Pour gagner en cohérence, nous allons créer une classe dans laquelle nous définirons ces deux champs, et nous ferons en sorte que les classes Wishlist, Item et Part en héritent. Django gère trois sortes d’héritage:
- L’héritage par classe abstraite
- L’héritage classique
- L’héritage par classe proxy.
Classes abstraites
L’héritage par classe abstraite consiste à déterminer une classe mère qui ne sera jamais instanciée. C’est utile pour définir des champs qui se répèteront dans plusieurs autres classes et surtout pour respecter le principe de DRY. Comme la classe mère ne sera jamais instanciée, ces champs seront en fait dupliqués physiquement, et traduits en SQL, dans chacune des classes filles.
class AbstractModel(models.Model): class Meta: abstract = True
created_at = models.DateTimeField(auto_now_add=True) updated_at = models.DateTimeField(auto_now=True)
class Wishlist(AbstractModel): pass
class Item(AbstractModel): pass
class Part(AbstractModel): passEn traduisant ceci en SQL, on aura en fait trois tables, chacune reprenant les champs created_at et updated_at, ainsi que son propre identifiant:
--$ python manage.py sql wish
BEGIN;CREATE TABLE "wish_wishlist" ( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "created_at" datetime NOT NULL, "updated_at" datetime NOT NULL);CREATE TABLE "wish_item" ( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "created_at" datetime NOT NULL, "updated_at" datetime NOT NULL);CREATE TABLE "wish_part" ( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "created_at" datetime NOT NULL, "updated_at" datetime NOT NULL);COMMIT;Une bonne pratique consiste à ajouter un “autre” identifiant pour un modèle susceptible d’être interrogé. Nous pensons ici à un UUID ou à un slug , qui permettrait d’avoir une sorte de clé sémantique associée à un object; ceci évite également d’avoir des identifiants qui soient trop facilement récupérables.
Héritage classique
L’héritage classique est généralement déconseillé, car il peut introduire très rapidement un problème de performances: en reprenant l’exemple introduit avec l’héritage par classe abstraite, et en omettant l’attribut abstract = True, on se retrouvera en fait avec quatre tables SQL:
- Une table
AbstractModel, qui reprend les deux champscreated_atetupdated_at - Une table
Wishlist - Une table
Item - Une table
Part.
A nouveau, en analysant la sortie SQL de cette modélisation, on obtient ceci:
--$ python manage.py sql wish
BEGIN; CREATE TABLE "wish_abstractmodel" ( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "created_at" datetime NOT NULL, "updated_at" datetime NOT NULL ) ; CREATE TABLE "wish_wishlist" ( "abstractmodel_ptr_id" integer NOT NULL PRIMARY KEY REFERENCES "wish_abstractmodel" ("id") ) ; CREATE TABLE "wish_item" ( "abstractmodel_ptr_id" integer NOT NULL PRIMARY KEY REFERENCES "wish_abstractmodel" ("id") ) ; CREATE TABLE "wish_part" ( "abstractmodel_ptr_id" integer NOT NULL PRIMARY KEY REFERENCES "wish_abstractmodel" ("id") ) ; COMMIT;Le problème est que les identifiants seront définis et incrémentés au niveau de la table mère. Pour obtenir les informations héritées, nous seront obligés de faire une jointure. En gros, impossible d’obtenir les données complètes pour l’une des classes de notre travail de base sans effectuer un join sur la classe mère.
Dans ce sens, cela va encore…
Mais imaginez que vous définissiez une classe Wishlist, de laquelle héritent les classes ChristmasWishlist et EasterWishlist: pour obtenir la liste complètes des listes de souhaits, il vous faudra faire une jointure externe sur chacune des tables possibles, avant même d’avoir commencé à remplir vos données.
Il est parfois nécessaire de passer par cette modélisation, mais en étant conscient des risques inhérents.
Classes Proxy
Lorsqu’on définit une classe de type proxy, on fait en sorte que cette nouvelle classe ne définisse aucun nouveau champ sur la classe mère. Cela ne change dès lors rien à la traduction du modèle de données en SQL, puisque la classe mère sera traduite par une table, et la classe fille ira récupérer les mêmes informations dans la même table: elle ne fera qu’ajouter ou modifier un comportement dynamiquement, sans ajouter d’emplacements de stockage supplémentaires.
Nous pourrions ainsi définir les classes suivantes:
class Wishlist(models.Model): name = models.CharField(max_length=255) description = models.CharField(max_length=2000) expiration_date = models.DateField()
@staticmethod def create(self, name, description, expiration_date=None): wishlist = Wishlist() wishlist.name = name wishlist.description = description wishlist.expiration_date = expiration_date wishlist.save() return wishlist
class ChristmasWishlist(Wishlist): class Meta: proxy = True
@staticmethod def create(self, name, description): christmas = datetime(current_year, 12, 31) w = Wishlist.create(name, description, christmas) w.save()
class EasterWishlist(Wishlist): class Meta: proxy = True
@staticmethod def create(self, name, description): expiration_date = datetime(current_year, 4, 1) w = Wishlist.create(name, description, expiration_date) w.save()Conclusions
Le modèle proposé par Django est fort couplé au coeur du framework, et si tous les composants peuvent être échangés avec quelques manipulations, le remplacement du modèle sera plus complexe à traiter. A côté de cela, il est extrêmement performant, permet énormément de choses, et vous fera gagner un temps précieux, tant en rapidité d’essais/erreurs, que de preuves de concept.
Dans les exemples ci-dessus, nous avons vu les différents types de champs, plusieurs représentations de relations, représentées par des clés étrangères (OneToOneField pour des relations 1-1, ForeignKey pour des relations 1-N ou ManyToManyField pour des relations N-M) d’une classe A vers une classe B.
Nous avons également vu des équivalences en SQL de ce que l’ORM est capable d’accomplir.