Architecture
If you think good architecture is expensive, try bad architecture.
— Brian Foote & Joseph Yoder
Autant il est normal que des classes, modules ou composants évoluent et changent d’interface ou de signature, autant les changements autorisés pour l’architecture générale sont nettement moins permissifs, dans la mesure où ceux-ci sont gouvernés par les frontières et interactions possibles avec le monde extérieur : l’objectif principal est de maximiser la capacité d’adaptation, tout en minimisant la maintenance qui pourrait être nécessaire.
Une bonne architecture a plusieurs objectifs :
- Maximiser les capacités d’adaptation, en rendant le système facile à lire, développer, maintenir et déployer ; l’objectif ultime étant de minimiser le coût de maintenance et de maximiser la productivité des développeurs,
- Minimiser le coût de maintenance, afin de maximiser la productivité des développeurs,
- Se garder le plus d’options possibles, en se concentrant sur les détails concrets (le type de base de données, la conception, …) le plus tard possible, tout en conservant la politique principale en ligne de mire. Ce dernier point permet de délayer ultérieurement certains choix techniques, et permet de concrétiser certaines décisions en ayant le plus d’éléments en main.
Derrière une bonne architecture, il y a aussi un investissement quant aux ressources qui seront nécessaires à faire évoluer l’application : une architecture ouverte et pouvant être étendue n’a d’intérêt que si le développement est suivi et que ses personnes en charge s’engagent à y investir du temps et en augmenter la qualité dès qu’un changement lié à l’évolution du projet aura un impact sur du code existant - ceci fera lentement (mais sûrement !) dériver la base de code vers une augmentation de la dette technique.
Faire évoluer correctement l’architecture d’un projet demande une bonne expérience, mais également un bon sens de l’observation, une attention portée aux détails et de la patience : il ne s’agit pas de se réveiller le matin et de se dire que “Aujourd’hui, je fais une bonne archi’ !”, ni de définir, dès le début d’un projet, le périmètre précès d’une application. A la place, il convient d’attendre, d’être attentif aux détails et à l’évolution du système, de limiter ou retarder au maximum les décisions qui peuvent l’être. Il convient de se projeter au plus loin dans la définition ce que le système pourra devenir, et de faire attention aux premières frictions : à chaque demande et nécessité de réévaluation, il conviendra de peser les pours et contre entre réaliser un choix d’implémentation et continuer à l’ignorer, jusqu’à ce que cet équilibre atteindra son point d’inflexion cite:[clean_architecture(229)].
Modules
- SRP - Single responsibility principle - Principe de Responsabilité unique
- OCP - Open-closed principle
- LSP - Liskov Substitution
- ISP - Interface ségrégation principle
- DIP - Dependency Inversion Principle
Single Responsibility Principle
Le principe de responsabilité unique conseille de disposer de concepts ou domaines d’activité qui ne s’occupent chacun que d’une et une seule chose. Ceci rejoint (un peu) la Philosophie Unix, documentée par Doug McIlroy et qui demande de “faire une seule chose, mais de le faire bien” cite:[unix_philosophy].
Selon ce principe, une classe ou un élément de programmation ne doit donc pas avoir plus d’une seule raison de changer.
Plutôt que de centraliser le maximum de code à un seul endroit ou dans une seule classe par convenance ou commodité, le principe de responsabilité unique suggère que chaque classe soit responsable d’un et un seul concept.
Une manière de voir les choses consiste à différencier les acteurs ou les intervenants: imaginez disposer d’une classe représentant des données de membres du personnel; ces données pourraient être demandées par trois acteurs:
- Le CFO (Chief Financial Officer)
- Le CTO (Chief Technical Officer)
- Le COO (Chief Operating Officer)
Chacun d’entre eux aura besoin de données et d’informations relatives à ces membres du personnel, et provenant donc d’une même source de données centralisée. Mais chacun d’entre eux également besoin d’une représentation différente ou de traitements distincts cite:[clean_architecture].
Nous sommes d’accord qu’il s’agit à chaque fois de données liées aux employés; celles-ci vont cependant un cran plus loin et pourraient nécessiter des ajustements spécifiques en fonction de l’acteur concerné et de la manière dont il souhaite disposer des données. Dès que possible, identifiez les différents acteurs et demandeurs, en vue de prévoir les modifications qui pourraient être demandées par l’un d’entre eux.
Dans le cas d’un élément de code centralisé, une modification induite par un des acteurs pourrait ainsi avoir un impact sur les données utilisées par les autres.
Vous trouverez ci-dessous une classe Document, dont chaque instance est représentée par trois propriétés: son titre, son contenu et sa date de publication.
Une méthode render permet également de proposer (très grossièrement) un type de sortie et un format de contenu: XML ou Markdown.
class Document: def __init__(self, title, content, published_at): self.title = title self.content = content self.published_at = published_at
@property def iso_published_date(self): return self.published_at.iso_format()
def render(self, format_type): if format_type == "XML": return f"""<?xml version = "1.0"?> <document> <title>{self.title}</title> <content>{self.content}</content> <publication_date>{self.iso_published_date}</publication_date> </document>"""
if format_type == "Markdown": import markdown return markdown.markdown(self.content)
raise ValueError( "Format type '{}' is not known".format(format_type) )Lorsque nous devrons ajouter un nouveau rendu (Atom, OpenXML, …) il sera nécessaire de modifier la classe Document.
Ceci n’est:
- Ni intuitif : ce n’est pas le document qui doit savoir dans quels formats il peut être converti
- Ni conseillé : lorsque nous aurons quinze formats différents à gérer, il sera nécessaire d’avoir autant de conditions dans cette méthode.
En suivant le principe de responsabilité unique, une bonne pratique consiste à créer une nouvelle classe de rendu pour chaque type de format à gérer:
class Document: def __init__(self, title, content, published_at): self.title = title self.content = content self.published_at = published_at
class DocumentRenderer: def render(self, document): if format_type == "XML": return f"""<?xml version = "1.0"?> <document> <title>{self.title}</title> <content>{self.content}</content> <publication_date>{self.published_at.isoformat()}</publication_date> </document>"""
if format_type == "Markdown": import markdown return markdown.markdown(self.content)
raise ValueError( "Format type '{}' is not known".format( format_type ) )A présent, lorsque nous devrons ajouter un nouveau format de prise en charge, il nous suffira de modifier la classe DocumentRenderer, sans que la classe Document ne soit impactée.
En parallèle, le jour où nous ajouterons un champ champ author à une instance de type Document, rien ne dit que le rendu devra en tenir compte; nous modifierons donc
notre classe pour y ajouter le nouveau champ sans que cela n’impacte nos différentes manières d’effectuer un rendu.
Un autre exemple consiterait à faire communiquer une méthode avec une base de données: ce ne sera pas à cette méthode à gérer l’inscription d’une exception à un emplacement spécifique (emplacement sur un disque, …) : cette action doit être prise en compte par une autre classe (ou un autre concept ou composant), qui s’occupera de définir elle-même l’emplacement où l’évènement sera enregistré, que ce soit dans une base de données, une instance Graylog ou un fichier. Cette manière de structurer le code permet de centraliser la configuration d’un type d’évènement à un seul endroit, ce qui augmente ainsi la testabilité globale du projet.
L’équivalent du principe de responsabilité unique au niveau des composants sera le Common Closure Principle .
Au niveau architectural, cet équivalent correspondra aux frontières.
Open-Closed Principle
“_For software systems to be easy to change, they must be designed to allow the behavior to change by adding new code instead of changing existing code.”
L’objectif est de rendre le système facile à étendre, en limitant l’impact qu’une modification puisse avoir.
Reprendre notre exemple de modélisation de documents parle de lui-même :
- Des données que nous avons converties dans un format spécifique pourraient à présent devoir être présentées dans une page web.
- Et demain, ce sera dans un document PDF,
- Et après demain, dans un tableur Excel.
La source de ces données reste la même (au travers d’une couche de présentation) : c’est leur mise en forme qui diffère à chaque fois. L’application n’a pas à connaître les détails d’implémentation : elle doit juste permettre une forme d’extension, sans avoir à appliquer quelconque modification en son cœur.
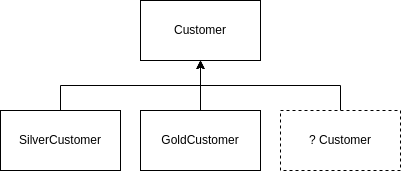
Un des principes essentiels en programmation orientée objets concerne l’héritage de classes et la surcharge de méthodes: plutôt que de partir sur une série de comparaisons comme nous l’avons initisée plus tôt pour définir le comportement d’une instance, il est parfois préférable de définir une nouvelle sous-classe, qui surcharge une méthode bien précise. Pour prendre un nouvel exemple, nous pourrions ainsi définir trois classes:
- Une classe
Customer, pour laquelle la méthodeGetDiscountne renvoit rien; - Une classe
SilverCustomer, pour laquelle la méthode revoit une réduction de 10%; - Une classe
GoldCustomer, pour laquelle la même méthode renvoit une réduction de 20%.
Si nous devions rencontrer un nouveau type de client, il nous suffira de créer une nouvelle sous-classe, implémentant la réduction que nous souhaitons lui offrir. Ceci évite d’avoir à gérer un ensemble conséquent de conditions dans la méthode initiale, en fonction d’une variable ou d’un paramètre - ici, le type de client.
Nous passerions ainsi de ceci :
class Customer(): def __init__(self, customer_type: str): self.customer_type = customer_type
def get_discount(customer: Customer) -> int: if customer.customer_type == "Silver": return 10 elif customer.customer_type == "Gold": return 20 return 0
>>> jack = Customer("Silver")>>> jack.get_discount()10A ceci :
class Customer(): def get_discount(self) -> int: return 0
class SilverCustomer(Customer): def get_discount(self) -> int: return 10
class GoldCustomer(Customer): def get_discount(self) -> int: return 20
>>> jack = SilverCustomer()>>> jack.get_discount()10Notre classe Customer est à présent fermée à toute nouvelle modification, mais ouverte à des extensions lorsque de nouveaux types de clients devront être ajoutés au projet. En résumé: nous fermons la classe Customer à toute modification, mais nous ouvrons la possibilité de créer de nouvelles extensions en ajoutant de nouveaux types héritant de Customer.
De cette manière, nous simplifions également la maintenance de la méthode get_discount, dans la mesure où elle dépend directement du type dans lequel elle est implémentée.
Nous pouvons également appliquer ceci à notre exemple sur les rendus de document, où le code suivant :
class Document: def __init__(self, title, content, published_at): self.title = title self.content = content self.published_at = published_at
def render(self, format_type): if format_type == "XML": return f"""<?xml version = "1.0"?> <document> <title>{self.title}</title> <content>{self.content}</content> <publication_date>{self.published_at.isoformat()}</publication_date> </document>"""
if format_type == "Markdown": import markdown return markdown.markdown(self.content)
raise ValueError( "Format type '{}' is not known".format(format_type) )devient le suivant :
class Renderer: def render(self, document): raise NotImplementedError
class XmlRenderer(Renderer): def render(self, document) return """<?xml version = "1.0"?> <document> <title>{}</title> <content>{}</content> <publication_date>{}</publication_date> </document>""".format( document.title, document.content, document.published_at.isoformat() )
class MarkdownRenderer(Renderer): def render(self, document): import markdown return markdown.markdown(document.content)Lorsque nous ajouterons notre nouveau type de rendu, nous ajouterons simplement une nouvelle classe de rendu qui héritera de Renderer.
Liskov Substitution Principle
Le principe de substitution fait qu’une classe héritant d’une autre classe doit se comporter de la même manière que cette dernière. Il n’est pas question que la sous-classe n’implémente pas ou n’ait pas besoin de certaines méthodes, alors que celles-ci sont disponibles sa classe parente. Mathématiquement, ce principe peut être défini de la manière suivante:
[… if S is a subtype of T, then objects of type T in a computer program may be replaced with objects of type S (i.e., objects of type S may be substituted for objects of type T), without altering any of the desirable properties of that program (correctness, task performed, etc.).
http://en.wikipedia.org/wiki/Liskov_substitution_principle[Wikipédia].
Let q(x) be a property provable about objects x of type T. Then q(y) should be provable for objects y of type S, where S is a subtype of T.
— http://en.wikipedia.org/wiki/Liskov_substitution_principle[Wikipédia aussi]
Ce n’est donc pas parce qu’une classe a besoin d’une méthode définie dans une autre classe qu’elle doit forcément en hériter. Cela bousillerait le principe de substitution, dans la mesure où une instance de cette classe pourra toujours être considérée comme étant du type de son parent.
Petit exemple pratique: si nous définissons une méthode make_some_noise et une méthode eat sur une classe Duck, et qu’une réflexion avancée (et sans doute un peu alcoolisée) nous dit que “Puisqu’un Lion fait aussi du bruit, faisons le hériter de notre classe ‘Canard‘”, nous allons nous retrouver avec ceci:
class Duck: def make_some_noise(self): print("Kwak")
def eat(self, thing): if thing in ("plant", "insect", "seed", "seaweed", "fish"): return "Yummy!" raise IndigestionError("Arrrh")
class Lion(Duck): def make_some_noise(self): print("Roaaar!")Le principe de substitution de Liskov suggère qu’une classe doit toujours pouvoir être considérée comme une instance de sa classe parente, et doit pouvoir s’y substituer. Dans notre exemple, cela signifie que nous pourrons tout à fait accepter qu’un lion se comporte comme un canard et adore manger des plantes, insectes, graines, algues et du poisson. Miam ! Nous vous laissons tester la structure ci-dessus en glissant une antilope dans la boite à goûter du lion, ce qui nous donnera quelques trucs bizarres (et un lion atteint de botulisme).
Pour revenir à nos exemples de rendus de documents, nous aurions pu faire hériter notre MarkdownRenderer de la classe XmlRenderer:
class XmlRenderer: def render(self, document) return """<?xml version = "1.0"?> <document> <title>{}</title> <content>{}</content> <publication_date>{}</publication_date> </document>""".format( document.title, document.content, document.published_at.isoformat() )
class MarkdownRenderer(XmlRenderer): def render(self, document): import markdown return markdown.markdown(document.content)Si nous décidons à un moment d’ajouter une méthode d’entête au niveau de notre classe de rendu XML, notre rendu en Markdown héritera irrémédiablement de cette même méthode:
class XmlRenderer: def header(self): return """<?xml version = "1.0"?>"""
def render(self, document) return """{} <document> <title>{}</title> <content>{}</content> <publication_date>{}</publication_date> </document>""".format( self.header(), document.title, document.content, document.published_at.isoformat() )
class MarkdownRenderer(XmlRenderer): def render(self, document): import markdown return markdown.markdown(document.content)Le code ci-dessus ne porte pas immédiatement à conséquence, mais dès que nous invoquerons la méthode header() sur une instance de type MarkdownRenderer, nous obtiendrons un bloc de déclaration XML (<?xml version = "1.0"?>) pour un fichier Markdown, ce qui n’aura aucun sens.
En revenant à notre proposition d’implémentation, suite au respect d’Open-Closed, une solution serait de n’implémenter la méthode header() qu’au niveau de la classe XmlRenderer :
class Renderer: def render(self, document): raise NotImplementedError
class XmlRenderer(Renderer): def header(self): return """<?xml version = "1.0"?>"""
def render(self, document) return """{} <document> <title>{}</title> <content>{}</content> <publication_date>{}</publication_date> </document>""".format( self.header(), document.title, document.content, document.published_at.isoformat() )
class MarkdownRenderer(Renderer): def render(self, document): import markdown return markdown.markdown(document.content)Interface Segregation
Le principe de ségrégation d’interface suggère d’exposer uniquement les opérations nécessaires à l’exécution d’un contexte. Ceci limite la nécessité de recompiler un module, et évite ainsi d’avoir à redéployer l’ensemble d’une application alors qu’il suffirait de déployer un nouveau fichier JAR ou une DLL au bon endroit.
“The lesson here is that depending on something that carries baggage that you don’t need can cause you troubles that you didn’t except.” cite:[clean_architecture(86)]
Plus simplement, plutôt que de dépendre d’une seule et même (grosse) interface présentant un ensemble conséquent de méthodes, il est proposé d’exploser cette interface en plusieurs (plus petites) interfaces. Ceci permet aux différents consommateurs de n’utiliser qu’un sous-ensemble précis d’interfaces, répondant chacune à un besoin précis, et permet donc à nos clients de ne pas dépendre de méthodes dont ils n’ont pas besoin.
GNU/Linux Magazine propose un exemple d’interface cite:[gnu_linux_mag_hs_104(37-42)] permettant d’implémenter une imprimante :
interface IPrinter{ public abstract void printPage(); public abstract void scanPage(); public abstract void faxPage();}
public class Printer{ protected string name;
public Printer(string name) { this.name = name; }}L’implémentation d’une imprimante multifonction aura tout son sens:
public class AllInOnePrinter extends Printer implements IPrinter{ public AllInOnePrinter(string name) { super(name); }
public void printPage() { System.out.println(this.name + ": Impression"); }
public void scanPage() { System.out.println(this.name + ": Scan"); }
public void faxPage() { System.out.println(this.name + ": Fax"); }}Tandis que l’implémentation d’une imprimante premier-prix ne servira pas à grand chose :
public class FirstPricePrinter extends Printer implements IPrinter{ public FirstPricePrinter(string name) { super(name); }
public void printPage() { System.out.println(this.name + ": Impression"); }
public void scanPage() { System.out.println(this.name + ": Fonctionnalité absente"); }
public void faxPage() { System.out.println(this.name + ": Fonctionnalité absente"); }}L’objectif est donc de découpler ces différentes fonctionnalités en plusieurs interfaces bien spécifiques, implémentant chacune une opération isolée :
interface IPrinterPrinter{ public abstract void printPage();}
interface IPrinterScanner{ public abstract void scanPage();}
interface IPrinterFax{ public abstract void faxPage();}Cette réflexion s’applique à n’importe quel composant : votre système d’exploitation, les librairies et dépendances tierces, les variables déclarées, … Quel que soit le composant que l’on utilise ou analyse, il est plus qu’intéressant de se limiter uniquement à ce dont nous avons besoin plutôt que d’embarquer le must absolu qui peut faire 1000x fonctions de plus que n’importe quel autre produit, alors que seules deux d’entre elles seront nécessaires.
En Python, ce comportement est inféré lors de l’exécution, et donc pas vraiment d’application pour ce contexte d’étude : de manière plus générale, les langages dynamiques sont plus flexibles et moins couplés que les langages statiquement typés, pour lesquels l’application de ce principe-ci permettrait de juste mettre à jour une DLL ou un JAR sans que cela n’ait d’impact sur le reste de l’application.
Il est ainsi possible de trouver quelques horreurs, et ce dans tous les langages :
.Définition et utilisation d’un module isOdd, basé sur un autre module isNumber (alors qu’un typeof() == 'number' ferait très bien l’affaire)
/*!* is-odd <https://github.com/jonschlinkert/is-odd>** Copyright (c) 2015-2017, Jon Schlinkert.* Released under the MIT License.*/'use strict';
const isNumber = require('is-number');
module.exports = function isOdd(value) {
const n = Math.abs(value);
if (!isNumber(n)) { throw new TypeError('expected a number'); }
if (!Number.isInteger(n)) { throw new Error('expected an integer'); }
if (!Number.isSafeInteger(n)) { throw new Error('value exceeds maximum safe integer'); }
return (n % 2) === 1;}Voire, son opposé, qui dépend évidemment du premier :
.Réutilisation du module isOdd (utilisant lui-même le module is-number en JavaScript pour définir un nouveau module isEven
/*!* is-even <https://github.com/jonschlinkert/is-even>** Copyright (c) 2015, 2017, Jon Schlinkert.* Released under the MIT License.*/'use strict';
var isOdd = require('is-odd');
module.exports = function isEven(i) { return !isOdd(i);};Il ne s’agit que d’un simple exemple, mais qui tend à une seule chose : gardez les choses simples (et, éventuellement, stupides).
Dans l’exemple ci-dessus, l’utilisation du module is-odd requière déjà deux dépendances:
is-evenis-number
Imaginez la suite.
Réduire le nombre de dépendances accélère également l’intégration d’une personne souhaitant participer au projet : n’ajoutez pas de nouvelles dépendances à moins que leur plus-value ne surpasse le temps qu’il sera nécessaire à vos développeurs actuels et futurs pour en appréhender toutes les fonctionnalités cite:[django_for_startup_founders]. Soyez intelligents et n’ajoutez pas systématiquement une nouvelle dépendance ou fonctionnalité uniquement parce qu’elle est disponible, et maintenez la documentation nécessaire à une utilisation cohérente d’une dépendance par rapport à vos objectifs et au reste de l’application
Conserver des dépendances à jour peut facilement vous prendre 25% de votre temps cite:[django_for_startup_founders] : dès que vous arrêterez de les suivre, vous risquez de rencontrer des bugs mineurs, des failles de sécurité, voire qu’elles ne soient plus du tout compatibles avec d’autres morceaux de vos applications.
Dependency Inversion Principle
Dans une architecture conventionnelle, les composants de haut-niveau dépendent directement des composants de bas-niveau. L’inversion de dépendances stipule que c’est le composant de haut-niveau qui possède la définition de l’interface dont il a besoin, et le composant de bas-niveau qui l’implémente. L’objectif est que les interfaces soient les plus stables possibles, afin de réduire au maximum les modifications qui pourraient y être appliquées. De cette manière, toute modification fonctionnelle pourra être directement appliquée sur le composant de bas-niveau, sans que l’interface ne soit impactée.
“The dependency inversion principle tells us that the most flexible systems are those in which source code dependencies refer only to abstractions, not to concretions cite:[clean_architecture] .”
L’injection de dépendances est un patron de programmation qui suit le principe d’inversion de dépendances.
Django est bourré de ce principe, que ce soit pour les middlewares ou pour les connexions aux bases de données. Lorsque nous écrivons ceci dans notre fichier de configuration,
...
MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware',]
...Django ira simplement récupérer chacun de ces middlewares, qui répondent chacun à une https://docs.djangoproject.com/en/4.0/topics/http/middleware/#writing-your-own-middleware[interface clairement définie], dans l’ordre.
Il n’y a donc pas de magie : l’interface exige une signature particulière, tandis que l’implémentation effective n’est réalisée qu’au niveau le plus bas. C’est ensuite le développeur qui va simplement brancher ou câbler des fonctionnalités au niveau du framework, en les déclarant au bon endroit. Pour créer un nouveau middleware, il nous suffirait d’implémenter de nouvelles fonctionnalités au niveau du code code suivant et de l’ajouter dans la configuration de l’application, au niveau de la liste de ceux qui sont déjà actifs :
def simple_middleware(get_response): # One-time configuration and initialization.
def middleware(request): # Code to be executed for each request before # the view (and later middleware) are called.
response = get_response(request)
# Code to be executed for each request/response after # the view is called.
return response
return middlewareDans d’autres projets écrits en Python, ce type de mécanisme peut être implémenté relativement facilement en utilisant les modules https://docs.python.org/3/library/importlib.html[importlib] et la fonction getattr.
Un autre exemple concerne les bases de données: pour garder un maximum de flexibilité, Django ajoute une couche d’abstraction en permettant de spécifier le moteur de base de données que vous souhaiteriez utiliser, qu’il s’agisse d’SQLite, MSSQL, Oracle, PostgreSQL ou MySQL/MariaDB cite:[howfuckedismydatabase].
D’un point de vue architectural, nous ne devons pas nous soucier de la manière dont les données sont stockées, s’il s’agit d’un disque magnétique, de mémoire vive, … En fait, on ne devrait même pas savoir s’il y a un disque du tout. Et Django le fait très bien pour nous.
Le code qui implémente des politiques de haut-niveau ne devrait pas dépendre de code qui implémente des détails de bas-niveau. A l’inverse, ce sont ces détails qui doivent dépendre de ces politiques. cite:[clean_architecture(59)]
En termes architecturaux, ce principe autorise une définition des frontières, et en permettant une séparation claire en inversant le flux de dépendances et en faisant en sorte que les règles métiers n’aient aucune connaissance des interfaces graphiques qui les exploitent ou des moteurs de bases de données qui les stockent. Ceci autorise une forme d’immunité entre les composants.
Cohésion des composants
“Si les classes et modules permettent de définir des murs et des pièces, les composants permettent de définir des immeubles en (ré)utilisant ces mêmes briques et murs.”
— Robert C. Martin
Définir quelles classes appartiennent à quels composants constitue une décision importante d’une bonne architecture. Les trois principes suivants constituent la base cite:[clean_architecture(104)] :
- REP - Reuse/Release Equivalence Principle,
- CCP - Common Closure Principle,
- CRP - Common Reuse Principle,
Nous verrons plus loin que ces principes ont un lien très fort avec les différents apps que nous pourrons trouver au niveau d’un projet Django : chacune de ces applications sera composée d’un ensemble de plusieurs classes, chacune d’entre elles ayant des liens (clés étrangères, requêtes, recherches croisées, …) vers d’autres classes - appartenant potentiellement à d’autres modules ou composants.
Reuse/Release Equivalence Principle
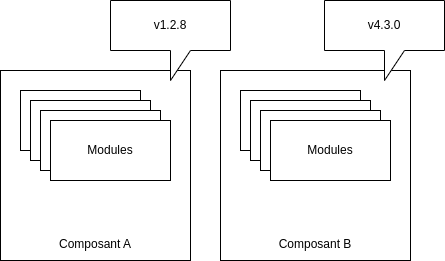
Nous vivons dans l’ère de la réutilisation logicielle - et ceci n’est possible qu’au travers d’un mécanisme de mise à disposition, suivi par des versions numérotées (ou, a minima identifiées). Au chapitre précédent, nous parlions de la nécessité d’épingler les versions pour définir nos composants - et les risques de ne pas le faire ; architecturalement, ceci signifie qu’un ensemble de modules doit être solidaire, et donc, que cet ensemble de classes et modules doit pouvoir être mis à disposition de manière unitaire.
Common Closure Principle
Là où le principe précédent restait relativement flou, l’objectif de ce principe-ci consiste à définir une politique de regroupement de plusieurs éléments de bas niveau dans un composant de plus haut niveau cite:[clean_architecture(105)]:
- Regroupez dans un même composants les classes qui changent pour une même raison et au même moment.
- Séparez des des composants différents les classes qui changent à différents moments ou pour des raisons différentes cite:[crime_scene].
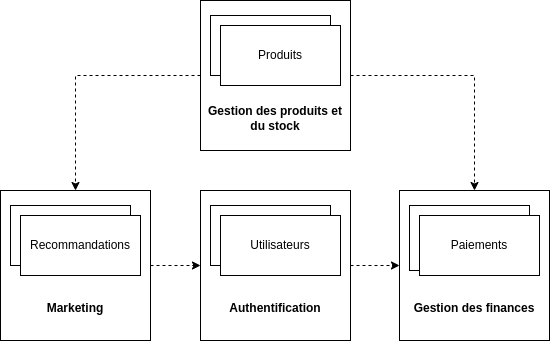
Common Reuse Principle
Ce principe guide également dans le choix d’association d’un module à un composant : si deux classes sont tellement couplées qu’elles évoluent simultanément, c’est un signe qu’il faut les conserver dans le même composant.
Couplage des composants
Dans la section précédente, nous avons vu trois principes liés à la cohésion des composants. Ceux-ci évoluant dans un environnement relativement complexe, il arrive inmanquablement qu’ils subissent une forme de couplage et qu’ils commencent à dépendre les uns des autres.
- ADP - Acyclic Dependency Principle,
- SDP - Stable Dependency Principle,
- SAP - Stable Abstraction Principle.
Acyclic Dependency Principle
Le principe de gestion acyclique des dépendances conseille d’éviter qu’une dépendance ne dépende elle-même du module dont elle dépend.
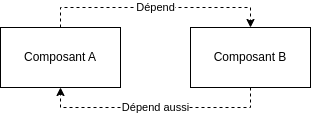
Dans ce type de cas, il convient d’extraire de nos différents composants les dépendances communes dont ils ont besoin, afin de les placer dans un composant supplémentaire.
En supposant que notre composant A dispose d’un module nécessaire au fonctionnement de B et que notre composant B dispose d’un module nécessaire au fonctionnement de A, il convient alors de sortir ces deux modules dans un composant C dont A et B pourront dépendre sans que nous ne créions de cycle dans le graph de dépendances :
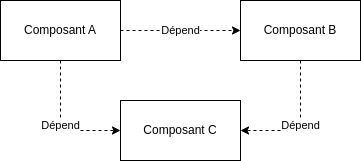
Nous voyons clairement que les seuls “chemins” possibles sont A->B->C ou A->C, et qu’il est impossible de remonter de C vers A, de C vers B ou de B vers A :
Stable Dependency Principle
Ce principe définit une formule de stabilité pour les composants, en fonction de leur faculté à être modifié et leurs interdépendances : au plus un composant est nécessaire ou critique, au plus il devra être stable, dans la mesure chaque changement aura un impact sur l’ensemble des services et composants qui en consomment les fonctionnalités.
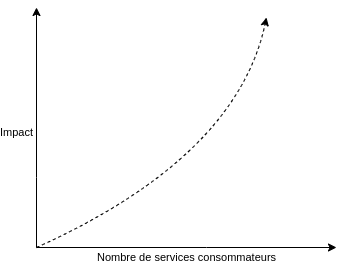
Cette facilité de modification nécessite de passer par des interfaces (donc, rarement modifiées, par définition) :
En C++, cela correspond aux mots clés #include. Pour faciliter cette stabilité, il convient de passer par des interfaces (donc, rarement modifiées, par définition).
En Python, ce ratio pourrait être calculé au travers des import, via les AST.
Stable Abstraction Principle
Le principe de stabilité d’abstraction définit et compare la stabilité des politiques et interfaces de haut niveau par rapport à celles des composants plus concrets.
Ce principe peut être vu comme une forme de modélisation du principe Open-Closed, mais appliquée aux composants :
- Ceux qui ne changent pas (ou pratiquement pas) le plus haut possible dans la hiérarchie des éléments,
- Ceux qui changent fréquemment, au plus bas, dans le sens de stabilité du flux.
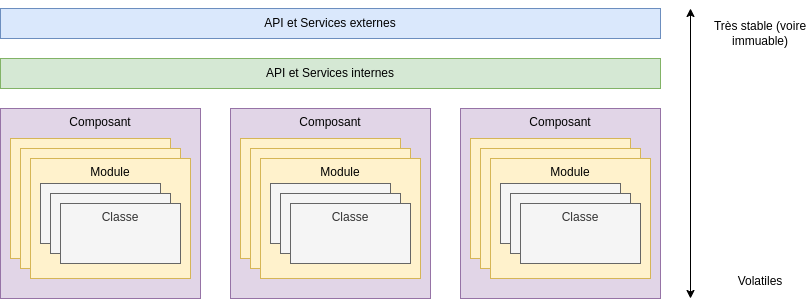
Conclusions
Au niveau des méthodes et fonctions
- Gardez vos méthodes/fonctions courtes. Pas plus de 15 lignes, en comptant les commentaires. Des exceptions sont possibles, mais dans une certaine mesure uniquement (pas plus de 6.9% de plus de 60 lignes; pas plus de 22.3% de plus de 30 lignes, au plus 43.7% de plus de 15 lignes et au moins 56.3% en dessous de 15 lignes). Oui, c’est dur à tenir, mais faisable.
- Conserver une complexité de McCabe en dessous de 5, c’est-à-dire avec quatre branches au maximum. A nouveau, si une méthode présente une complexité cyclomatique de 15, la séparer en 3 fonctions ayant chacune une complexité de 5 conservera la complexité globale à 15, mais rendra le code de chacune de ces méthodes plus lisible, plus maintenable.
- N’écrivez votre code qu’une seule fois: évitez les duplications, copie, etc.: imaginez qu’un bug soit découvert dans une fonction; il devra alors être corrigé dans toutes les fonctions qui auront été copiées/collées.
- Conservez de petites interfaces et signatures de fonctions/méthodes. Quatre paramètres, pas plus. Au besoin, refactorisez certains paramètres dans une classe ou une structure, qui sera plus facile à tester.
Au niveau des classes
- Privilégiez un couplage faible entre vos classes. Ceci n’est pas toujours possible, mais dans la mesure du possible, éclatez vos classes en fonction de leur domaine de compétences respectif. L’implémentation du service
UserNotificationsServicene doit pas forcément se trouver embarqué dans une classeUserService. De même, pensez à passer par une interface (commune à plusieurs classes), afin d’ajouter une couche d’abstraction. La classe appellante n’aura alors que les méthodes offertes par l’interface comme points d’entrée.
Dans la même veine, faites en sorte que les dépendances aillent toutes “dans le même sens”, ce qui limitera l’effet spaghetti associé au code, tout en améliorant sa lisibilité et l’intuitivité de sa compréhension.
Au niveau des composants
- Tout comme pour les classes, il faut conserver un couplage faible au niveau des composants également. Une manière d’arriver à ce résultat est de conserver un nombre de points d’entrée restreint, et d’éviter qu’il ne soit possible de contacter trop facilement des couches séparées de l’architecture. Pour une architecture n-tiers par exemple, la couche d’abstraction à la base de données ne peut être connue que des services; sans cela, au bout de quelques semaines, n’importe quelle couche de présentation risque de contacter directement la base de données, “juste parce qu’elle en a la possibilité”. Vous pourriez également passer par des interfaces, afin de réduire le nombre de points d’entrée connus par un composant externe (qui ne connaîtra par exemple que
IFileTransferavec ses méthodesputetget, et non pas les détailsd’implémentation complet d’une classeFtpFileTransferouSshFileTransfer). - Conserver un bon balancement au niveau des composants : évitez qu’un composant A ne soit un énorme mastodonte, alors que le composant juste à côté ne soit capable que d’une action. De cette manière, les nouvelles fonctionnalités seront mieux réparties parmi les différents systèmes, et les responsabilités seront plus faciles à gérer. Un conseil est d’avoir un nombre de composants compris entre 6 et 12 (idéalement, 12), et que chacun de ces composants soit approximativement de même taille.
De manière générale
- Conserver une densité de code faible : il n’est évidemment pas possible d’implémenter n’importe quelle nouvelle fonctionnalité en moins de 20 lignes de code; l’idée ici est que la réécriture du projet ne prenne pas plus de 20 hommes/mois. Pour cela, il faut (activement) passer du temps à réduire la taille du code existant: soit en faisant du refactoring (intensif), soit en utilisant des librairies existantes, soit en explosant un système existant en plusieurs sous-systèmes communiquant entre eux. Mais surtout, en évitant de copier/coller bêtement du code existant.
- Automatiser les tests, en ajoutant un environnement d’intégration continue dès le début du projet et en faisant vérifier par des outils automatiques tous les points ci-dessus.