Fiabilité, évolutivité et maintenabilité
“The primary cost of maintenance is in spelunking and risk”
— Robert C. Martin
Que l’utilisateur soit humain, bot automatique ou client Web, la finalité d’un développement est de fournir des applications résilientes, pouvant être mises à l’échelle et maintenables cite:[data_intensive(5)] :
-
Une application est résiliente lorsqu’elle continue à fournir un service correct (par rapport à un niveau de performances désiré), même quand des choses se passent mal. Ce type de système a la capacité:
-
D’anticiper certains types d’erreurs (ou de les gérer de manière propre), par exemple en proposant une solution de repli (fallback)
-
De rendre rapidement indisponibles les composants qui posent problème, de manière à ce que ceux-ci n’entraînent pas tout le système avec eux (fail fast)
-
De retirer certaines fonctionnalités non-critiques lorsqu’elles répondent plus lentement ou lorsqu’elles présentent un impact sur le reste de l’application (feature removal).
Lors d’un incident AWS, Netlix proposait des recommandations statiques et ne se basait plus sur des recommandations personnalisées. Ceci leur a permis de tenir six heures avant de décréter être impacté cite:[devops_handbook].
-
La mise à échelle consiste à autoriser le système à grandir - soit par le trafic pouvant être pris en charge, soit par son volume de données, soit par sa complexité.
-
La maintenabilité consiste à faire en sorte que toute intervention puisse être réalisée de manière productive: au fil du temps, il est probable que plusieurs personnes se succèdent à travailler sur l’évolution d’une application, qu’ils travaillent sur sa conception ou sur son exploitation.
Une manière de développer de telles applications consiste à suivre la méthodologie des 12 facteurs. Il s’agit d’une méthodologie consistant à suivre douze principes, qui permettent de:
- Faciliter la mise en place de phases d’automatisation; plus concrètement, de faciliter les mises à jour applicatives, simplifier la gestion de l’hôte qui héberge l’application ou les services, diminuer la divergence entre les différents environnements d’exécution et offrir la possibilité d’intégrer le projet dans un processus d’intégration continue ou déploiement continu.
- Faciliter l’intégration de nouveaux développeurs dans l’équipe ou de personnes souhaitant rejoindre le projet, dans la mesure où la construction d’un nouvel environnement sera grandement facilitée.
- Minimiser les divergences entre les différents environnements sur lesquels un projet pourrait être déployé, pour éviter de découvrir un bogue sur l’environnement de production qui serait impossible à reproduire ailleurs, simplement parce qu’un des composants varierait
- Augmenter l’agilité générale du projet, en permettant une meilleure évolutivité architecturale et une meilleure mise à l’échelle.
En pratique, les points ci-dessus permettront de gagner un temps précieux à la construction et à la maintenance de n’importe quel environnement - qu’il soit sur la machine du petit nouveau dans l’équipe, sur un serveur Azure/Heroku/Digital Ocean ou sur votre nouveau Raspberry Pi Zéro planqué à la cave.
Pour reprendre plus spécifiquement les différentes idées derrière cette méthode, nous trouvons des conseils concernant:
- Une base de code unique, suivie par un contrôle de versions
- Une déclaration explicite et une isolation des dépendances
- Configuration applicative
- Ressources externes
- La séparation des phases de constructions
- La mémoire des processus d’exécution
- La liaison des ports
- Une connaissance et une confiance dans les processus systèmes
- La possibilité d’arrêter élégamment l’application, tout en réduisant au minimum son temps de démarrage
- La similarité des environnements
- La gestion des journaux et des flux d’évènements
- L’isolation des tâches administratives
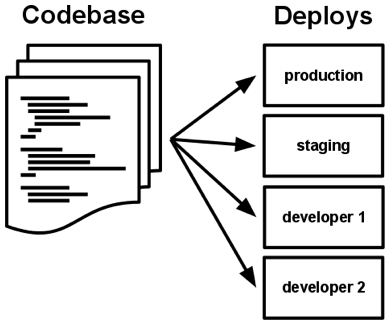
Une base de code unique, suivie par un contrôle de versions
Chaque déploiement de l’application, et quel que soit son environnement cible, se basera sur une source unique, afin de minimiser les différences que l’on pourrait trouver entre deux déploiements d’un même projet.
Git est reconnu dans l’industrie comme standard des systèmes de contrôles de versions, malgré une courbe d’apprentissage assez ardue. Comme dépôt, nous pourrons par exemple utiliser GitHub, Gitea ou Gitlab, suivant que vous ayez besoin d’une plateforme centralisée, propriétaire, payante ou auto-hébergée.
En résumé, il y a seulement une base de code par application, mais il y aura plusieurs déploiements de l’application. Un déploiement est une instance en fonctionnement de l’application. C’est, par exemple, le site en production, ou bien un ou plusieurs sites de validation.
En plus de cela, chaque développeur a une copie de l’application qui fonctionne son environnement local de développement, ce qui compte également comme un déploiement.
Comme l’explique Eran Messeri, ingénieur dans le groupe Google Developer Infrastructure: “Un des avantages d’utiliser un dépôt unique de sources, est qu’il permet un accès facile et rapide à la forme la plus à jour du code, sans aucun besoin de coordination cite:[devops_handbook(288-298)]. Ce dépôt n’est pas uniquement destiné à héberger le code source, mais également à d’autres artefacts et autres formes de connaissance, comme les standards de configuration (Chef recipes, Puppet manifests, …), outils de déploiement, standards de tests (y compris ce qui touche à la sécurité), outils d’analyse et de monitoring ou tutoriaux.
Déclaration explicite et isolation des dépendances
Chaque installation ou configuration doit être toujours réalisée de la même manière, et doit pouvoir être répétée quel que soit l’environnement cible. Ceci permet d’éviter que l’application n’utilise une dépendance qui ne soit installée que sur l’un des sytèmes de développement, et qu’elle soit difficile, voire impossible, à réinstaller sur un autre environnement.
Chaque dépendance devra être déclarée dans un fichier présent au niveau de la base de code. Lors de la création d’un nouvel environnement vierge, il suffira d’utiliser ce fichier comme paramètre afin d’installer les prérequis au bon fonctionnement de notre application, afin d’assurer une reproductibilité quasi parfaite de l’environnement d’exécution.
Il est important de bien “épingler” la version liée à chacune des dépendances de l’application. Ceci peut éviter des effets de bord comme une nouvelle version d’une librairie dans laquelle un bug aurait pu avoir été introduit.footnote:[Le paquet PyLint dépend par exemple d’Astroid; en janvier 2022, ce dernier a été mis à jour sans respecter le principe de versions sémantiques et introduisant une régression. PyLint spécifiait que sa dépendance avec Astroid devait respecter une version 2.9. Lors de sa mise à jour en 2.9.1, Astroid a introduit un changement majeur, qui faisait planter Pylint. L’épinglage explicite aurait pu éviter ceci.]. Prenez directement l’habitude de spécifier la version ou les versions compatibles: les librairies que vous utilisez comme dépendances évoluent, de la même manière que vos projets. Pour être sûr et certain le code que vous avez écrit continue à fonctionner, spécifiez la version de chaque librairie de dépendances. Entre deux versions d’une même librairie, des fonctions sont cassées, certaines signatures sont modifiées, des comportements sont altérés, etc. Il suffit de parcourirles pages de Changements incompatibles avec les anciennes versions de Django (ici, la 5.0) pour réaliser que certaines opérations ne sont pas anodines, et que sans filet de sécurité, c’est le mur assuré. Avec les mécanismes d’intégration continue et de tests unitaires, nous verrons plus loin comment se prémunir d’un changement inattendu.
Dans le cas de Python, la déclaration explicite et l’épinglage pourront notamment être réalisés au travers de PIP, Poetry ou uv. La majorité des langages modernes proposent des mécanismes similaires :
Configuration applicative
Il faut éviter d’avoir à recompiler/redéployer l’application simplement parce que :
- L’adresse du serveur de messagerie a été modifiée,
- Un protocole a changé en cours de route
- La base de données a été déplacée
- …
En pratique, toute information susceptible d’évoluer ou de changer (un seuil, une ressource externe, un couple utilisateur/mot de passe, …) doit se trouver dans un fichier ou dans une variable d’environnement, et doit être facilement modifiable.
En pratique, avec du code Python/Django, nous pourrions utiliser la libraririe django-environ, qui permet de gérer facilement ce fichier de configuration :
import environimport os
env = environ.Env( DEBUG=(bool, False))
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
environ.Env.read_env(os.path.join(BASE_DIR, '.env'))
DEBUG = env('DEBUG')SECRET_KEY = env('SECRET_KEY')
DATABASES = { # Parse database connection url strings # like psql://user:pass@127.0.0.1:8458/db 'default': env.db(),}
CACHES = { 'default': env.cache(),}Il suffira ensuite d’appeler ces variables grâce à from django.conf import settings pour récupérer la valeur qui aura été configurée.
Ceci permet de paramétrer facilement n’importe quel environnement, simplement en modifiant une variable de ce fichier de configuration.
Toute clé de configuration, qu’il s’agisse d’une chaîne de connexion vers une base de données, l’adresse d’un service Web externe, une clé d’API pour l’interrogation d’une ressource, d’un chemin vers un fichier à interprêter ou à transférer, …, ou n’importe quelle valeur susceptible d’évoluer, ne doit se trouver écrite en dur dans le code.
Il est important de ne surtout pas ajouter ce fichier .env dans le dépôt de sources: à aucun moment, nous ne devons y trouver de mot de passe ou d’information confidentielle en clair. footnote:Ainsi, nous pourrions faire une recherche sur Github pour retrouver certaines variables d’environnement qui auraient été laissées en dur dans le code source de certains projets.
Le dépôt suivant liste quelques idées de variables à rechercher, de même qu’une analyse récente du DockerHub indique que des milliers d’images contiennent des clés privées ou d’API.
Au moment de développer une nouvelle fonctionnalité, réfléchissez si l’un des paramètres utilisés risquerait de subir une modification ou s’il concerne un principe de sécurité.
Le risque de se retrouver avec une liste colossale de paramètres n’est cependant pas négligeable; pensez à leur assigner une variable par défaut
Par exemple, Gitea expose [https://docs.gitea.io/en-us/config-cheat-sheet/](la liste suivante de paramètres disponibles); il serait impossible d’utiliser cette plateforme si chacun d’entre eux devait obligatoirement être configuré avant de pouvoir démarrer une instance.
Ressources externes
Nous parlons de bases de données, de services de mise en cache, d’API externes, … L’application doit être capable d’effectuer des changements au niveau de ces ressources sans que son code ne soit modifié. Nous parlons alors de ressources attachées, dont la présence est nécessaire au bon fonctionnement de l’application, mais pour lesquelles le type n’est pas obligatoirement défini.
Nous voulons par exemple “une base de données” et “une mémoire cache”, et pas “une base MariaDB et une instance Memcached”, afin que les ressources externes puissent être attachées ou détachées en fonction de leur nécessité, et sans avoir à appliquer une modification au niveau du code applicatif.
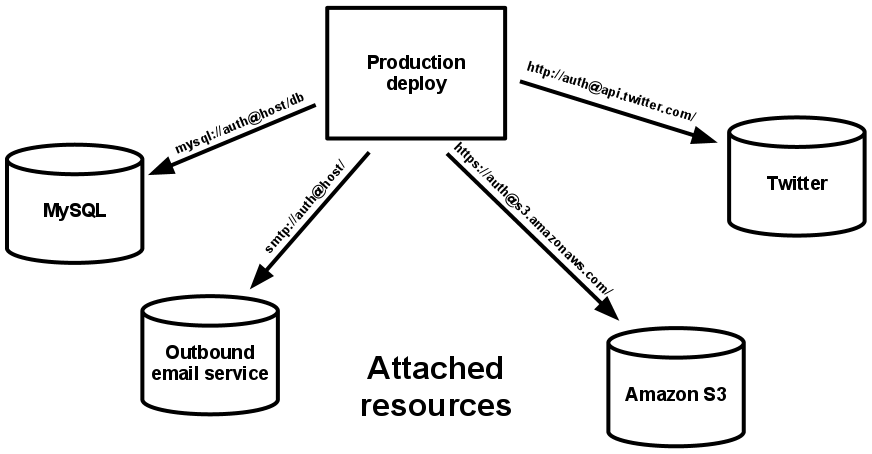
Nous serons ainsi ravis de pouvoir simplement modifier la chaîne de connexion sqlite:////tmp/my-tmp-sqlite.db en psql://user:pass@127.0.0.1:8458/db lorsque ce sera nécessaire, sans avoir à recompiler ou redéployer les modifications.
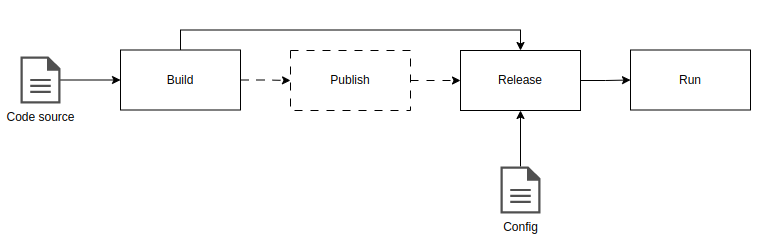
Séparation des phases de construction
- La construction (build) convertit un code source en un ensemble de fichiers exécutables, associé à une version et à une transaction dans le système de gestion de sources.
- La mise à disposition (release) associe cet ensemble à une configuration prête à être exécutée sur un environnement désigné,
- La phase d’exécution (run) démarre les processus nécessaires au bon fonctionnement de l’application.
Parmi les solutions possibles, nous pourrions nous baser sur les releases de Gitea, sur un serveur d’artefacts (Capistrano), voire directement au niveau de forge logicielle (Gitea, Github, Gitlab, …).
L’intérêt principal de cette scission des étapes, est que tout devient éphémère : si n’importe quel élément du pipeline devait être détruit, tous les artefacts et environnements pourront être reconstitués à partir de zéro, en utilisant les éléments qui se trouvent au niveau du dépôt.
Dans le cas de Python, la phase de construction (Build) correspondra plutôt à une phase d’empaquettage (packaging). Une fois préparée, la librairie ou l’application pourra être publiée sur pypi.org ou un dépôt géré en interne. La phase de release revient à associer une version spécifiquement empaquêtée pour l’associer à une configuration particulière.
Mémoires des processus d’exécution
Toute information stockée en mémoire ou sur disque ne doit pas altérer le comportement futur de l’application, par exemple après un redémarrage non souhaité.
Si une application devait rencontrer un problème - par exemple suite à un problème matériel, une coupure réseau, … -, il est nécessaire qu’elle puisse redémarrer rapidement, éventuellement en étant déployée sur un autre serveur. Toute information stockée physiquement sera alors perdue, puisque le contexte d’exécution aura été déplacée à un autre endroit. Lors de l’initialisation ou de la réinitialisation d’une application, la solution consiste à jouer sur les variables d’environnement et sur les informations que l’on pourra trouver au niveau des ressources attachées, afin de faire en sorte que les informations et données primordiales puissent être récupérées ou reconstruites, et donc réutilisées, sans altérer le comportement attendu.
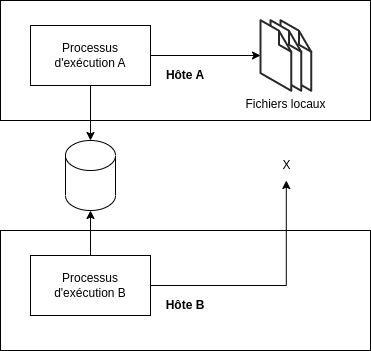
Ceci joue énormément sur les possibilités de mise à l’échelle: lors de l’ajout d’un nouveau serveur, il est indispensable qu’il puisse accéder à l’ensemble des informations nécessaires au bon fonctionnement de l’application.
Liaison des ports
Les applications 12-factors sont auto-contenues et peuvent fonctionner en autonomie totale. Elles doivent être joignables grâce à un mécanisme de ponts, où l’hôte qui s’occupe de l’exécution effectue lui-même la redirection vers l’un des ports ouverts par l’application, typiquement, en HTTP ou via un autre protocole.
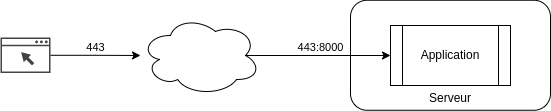
L’application fonctionne de manière autonome et expose un port (ici, le 8000). Le serveur (= l’hôte) choisit d’appliquer une correspondance entre “son” port 443 et le port offert par l’application (8000).
Concurrence
Nous pouvons créer et utiliser des processus supplémentaires pour tenir plus facilement une lourde charge ou dédier des particuliers pour certaines tâches, sans avoir à ajouter des CPU ou de la mémoire vive.
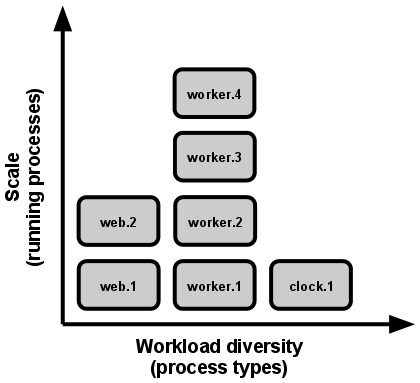
Processus disposables
Une application peut mourir à n’importe quel moment : partir du principe de disposability permet de s’assurer qu’une application puisse s’éteindre proprement et de manière élégante, afin d’être soit remplacée par une autre, soit redémarrer à un autre endroit.
En gérant dès le début l’envoi d’un signal de terminaison :
- Les requêtes en cours peuvent se terminer sans impact majeur,
- L’application est conçue pour démarrer rapidement,
- La création de nouveaux processus améliore la charge entre les processus existants.
Ceci autorise également l’exécution parallèle d’anciens et de nouveaux “types” de processus :
L’intégration de ces mécanismes dès les premières étapes de développement limitera les perturbations et facilitera la prise en compte d’arrêts inopinés (problème matériel, redémarrage du système hôte, etc.).
Similarité des environnements
Conservez les différents environnements aussi similaires que possible, et limitez les divergences entre un environnement de développement et de production.
Faire en sorte que tous les environnements soient les plus similaires possibles limite les divergences entre environnements, facilite les déploiements et limite la casse et la découverte de modules non compatibles, au plus proche de la phase de développement, selon le principe de la corde d’Andon.
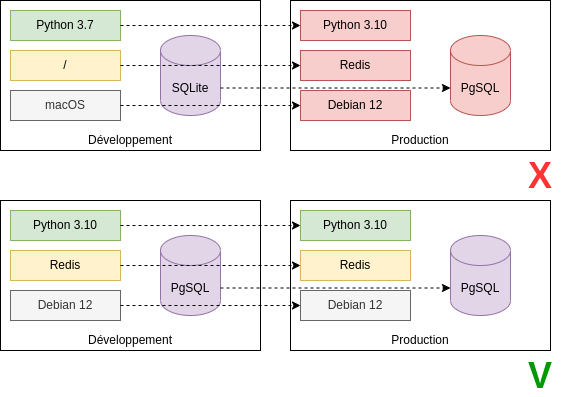
Ceci permet également de proposer à nos utilisateurs un bac à sable dans lequel ils pourront explorer et réaliser des expérimentations en toute sécurité, sans quel cela n’ait d’impact sur un réel environnement de production, où les conséquences pourraient être beaucoup plus graves.
Flux d’évènements
Les journaux d’exécution sont la seule manière pour une application de communiquer son état et de décrire ce qu’elle est occupée à faire ou à réaliser.
Que nous soyons en phase de développement sur le poste d’une personne de l’équipe, avec une sortie console ou sur une machine de production avec un envoi vers une instance Greylog ou Sentry, le routage des évènements doit être réalisé en fonction de la nécessité du contexte d’exécution et de sa criticité, pas d’un choix individuel appliqué à l’ensemble des plateformes cibles.

Cette phase est essentielle, dans la mesure où recevoir une erreur interne de serveur est une chose; pouvoir obtenir un minimum d’informations, voire un contexte de plantage complet en est une autre. La différence entre ces deux points vous fera, au mieux, gagner plusieurs heures sur l’identification ou la résolution d’un problème.
Une application ne doit jamais se soucier de l’endroit où les évènements qui la concerne seront écrits, mais se doit simplement de les envoyer sur la sortie stdout.
Isolation des tâches administratives
Il est important d’éviter qu’une migration ne puisse être démarrée depuis une URL de l’application, ou qu’un envoi massif de notifications ne soit accessible pour n’importe quel utilisateur: les tâches administratives ne doivent être accessibles qu’à un administrateur.
Les applications 12-facteurs favorisent les langages qui mettent un environnement REPL (pour Read, Eval, Print et Loop) à disposition (au hasard: Python ou Kotlin), ce qui facilite les étapes de maintenance.
Conclusions
“Good code is like a love letter to the next developer who will maintain it.”
— Addy Osmani
Une application devient nettement plus maintenable dès lors que l’équipe de développement suit de près les différentes étapes de sa conception, de la demande jusqu’à son aboutissement en production cite:[devops_handbook(293-294)]. Au fur et à mesure que le code est délibérément construit pour être maintenable, l’équipe gagne en rapidité, en qualité et en fiabilité de déploiement, ce qui facilite les tâches opérationnelles:
- Activation d’une télémétrie suffisante dans les applications et les environnements
- Conservation précise des dépendances nécessaires
- Résilience des services et plantage élégant (i.e. sans finir un SEGFAULT avec l’OS dans les choux et un écran bleu)
- Compatibilité entre les différentes versions (n+1, …)
- Gestion de l’espace de stockage associé à un environnement (pour éviter d’avoir un environnement de production qui fait 157 Tera-octets)
- Activation de la recherche dans les logs
- Traces des requêtes provenant des utilisateurs, indépendamment des services utilisés
- Centralisation de la configuration (via ZooKeeper, par exemple)